
ChatGPTやGemini、Claudeといった生成AIが普及する中、これらのサービスを動かすAI企業は、学習データや回答の材料を集めるために、日々インターネット上のサイトを自動で巡回しています。これを「AIクローラー」と呼びます。
GoogleのようなWeb検索クローラーとは異なり、AIクローラーの目的はあなたのコンテンツをAIの学習や応答生成に活用することです。サイトオーナーとして「うちのコンテンツをAIに使われたくない」「どのAIが来ているか把握したい」と感じるのは自然なことです。
Cloudflareが提供する AI Crawl Control は、こうしたAIクローラーの動きを可視化し、許可・ブロックまで管理できる機能です。
Googleアナリティクスのようなアクセス解析ツールは、ページ上のJavaScriptが実行されることでデータを収集します。
そのため、JavaScriptを実行しないAIクローラーの訪問は、そもそも計測できません。
Cloudflareはサイトへのすべての通信がCloudflareを経由する仕組み上、JavaScriptの実行有無に関わらず、インフラレベルでAIクローラーのアクセスを検知・識別できます。
これがAI Crawl Controlで正確な訪問数を把握できる理由です。
設定不要で全プランですぐに利用できます。
AI Crawl Controlの画面構成
Cloudflareのダッシュボードにログインし、対象のドメインを選択すると、左メニューに「AI Crawl Control」という項目があります。その中に以下の4つの項目があります。
| 項目名 | できること |
| 概要 | AI全体の活動をひと目で把握する |
| クローラー | どのAIが来ているか確認し、許可・ブロックを設定する |
| メトリクス | トラフィックの詳細データをグラフで確認する |
| ディレクティブ | robots.txtの状態やAIへの指示を管理する |
では、それぞれのページを詳しく見ていきましょう。
概要ページ — まず全体像を把握する
概要ページを開くと、サイトへのAIクローラーのアクセス状況がひと目でわかるサマリーが表示されます。
サマリーカードから何がわかるか
画面中央のサマリーには、たとえばこのような情報が表示されます。
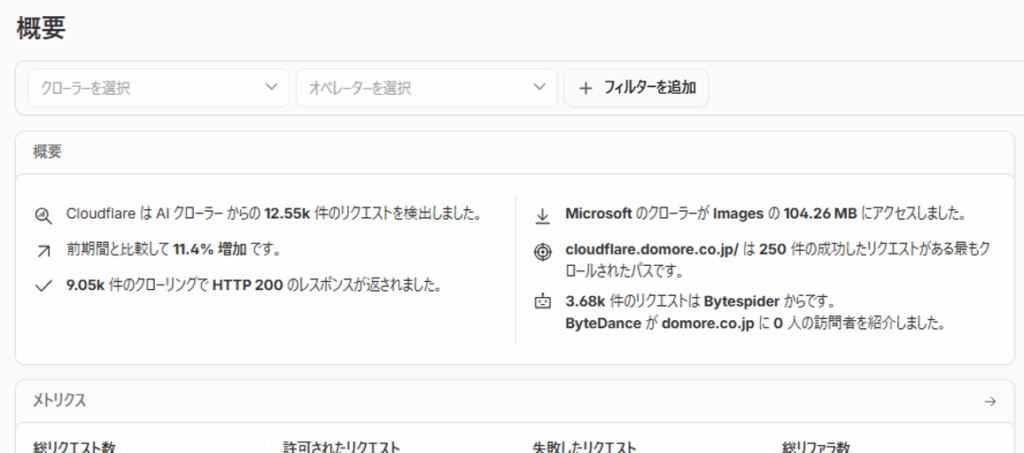
数字の大小より「前より増えているか減っているか」を継続的に見ていくことで効果を可視化できます。
クイックアクション — 3つの設定スイッチ
概要ページの右側には「クイックアクション」として、3つの機能のオン・オフスイッチがあります。
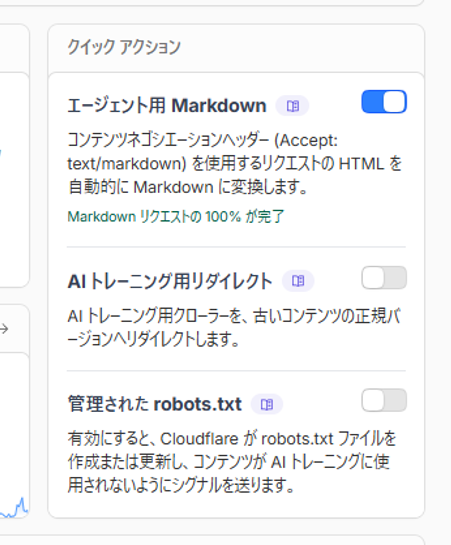
① エージェント用Markdown
AIクローラーがHTMLではなくMarkdown形式でコンテンツを取得できるようにする機能です。オンにするとAIが読みやすい形式でデータを受け取れます。サイトのコンテンツをAIに正確に理解してほしい場合に有効です。
② AIトレーニング用リダイレクト
AIの学習目的クローラーを、コンテンツの古い正規バージョンへリダイレクトする機能です。
③ 管理されたrobots.txt
オンにすると、Cloudflareが自動でrobots.txtを作成・更新し、AIトレーニング用クローラーに対して「学習に使わないでください」というシグナルを送ります。
これらの機能の有効化は必須ではありませんが、「エージェント用Markdown」は有効化しておくとよいでしょう。
クローラーページ — どのAIが来ているか、許可・ブロックを設定する
クローラーページでは、あなたのサイトにアクセスしているAIクローラーの一覧を確認でき、それぞれに対して「許可」か「ブロック」のアクションを設定できます。
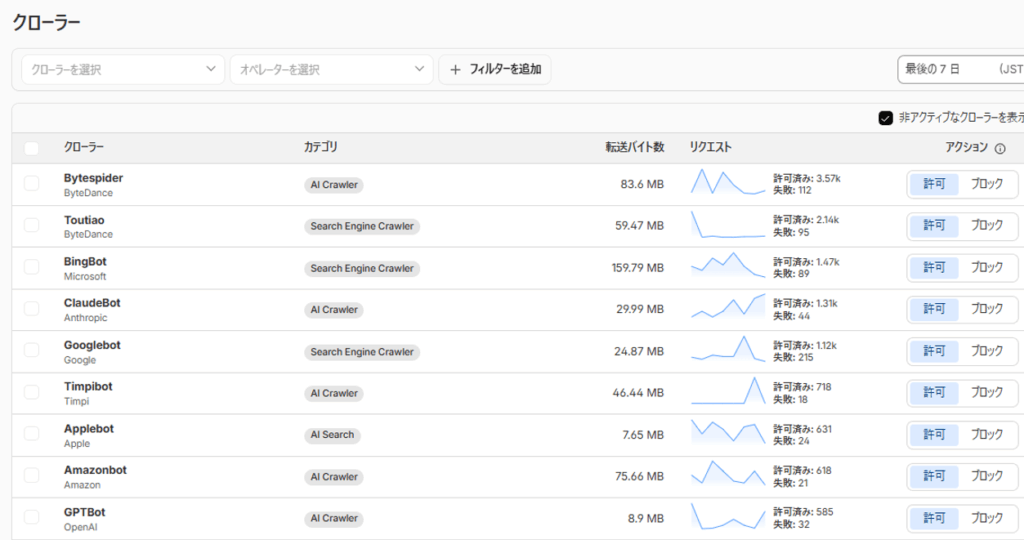
クローラー一覧の見方
テーブルには以下の情報が表示されます。
| 列名 | 内容 |
| クローラー | クローラーの名前と運営会社 |
| カテゴリ | AI Crawler / AI Search / AI Assistant / Archiverなど |
| 転送バイト数 | そのクローラーが取得したデータ量 |
| リクエスト | 許可・失敗の件数とトレンドグラフ |
| アクション | 許可 / ブロック の切り替え |
実際の画面では、ByteSpider(ByteDance)、BingBot(Microsoft)、ClaudeBot(Anthropic)、GPTBot(OpenAI)など、耳慣れた企業のクローラーが並んでいます。
アクセス数ゼロのクローラーも一覧に含まれており、「非アクティブなクローラーを表示」というチェックボックスで表示を切り替えられます。
カテゴリの意味
クローラーは用途によって分類されています。
- AI Crawler — コンテンツの収集・学習が目的
- AI Search — AI搭載の検索エンジン向け(Perplexityなど)
- AI Assistant — ChatGPTのような対話AIが使うクローラー
- Search Engine Crawler — BingやGoogleなど従来の検索エンジン
- Archiver — ウェブアーカイブ目的
許可・ブロックの設定方法
各クローラーの右端「アクション」列にある「許可」「ブロック」ボタンをクリックするだけで設定できます。ブロックを選ぶと、そのクローラーからのアクセスはCloudflare WAFによって遮断されます。
どのクローラーをブロックすべきか迷う場合は、まずアクセス数が多いものを確認し、「このAIに使われることに価値を感じるか」を基準に判断するとよいでしょう。
たとえばGoogleやBingはSEOにも関わるため、慎重に判断が必要です。
メトリクスページ — AIトラフィックの詳細データを読む
メトリクスページでは、AIクローラーのアクセスデータをさまざまな角度からグラフで確認できます。概要ページよりも詳しいデータが必要なときに使います。
AI紹介トラフィック
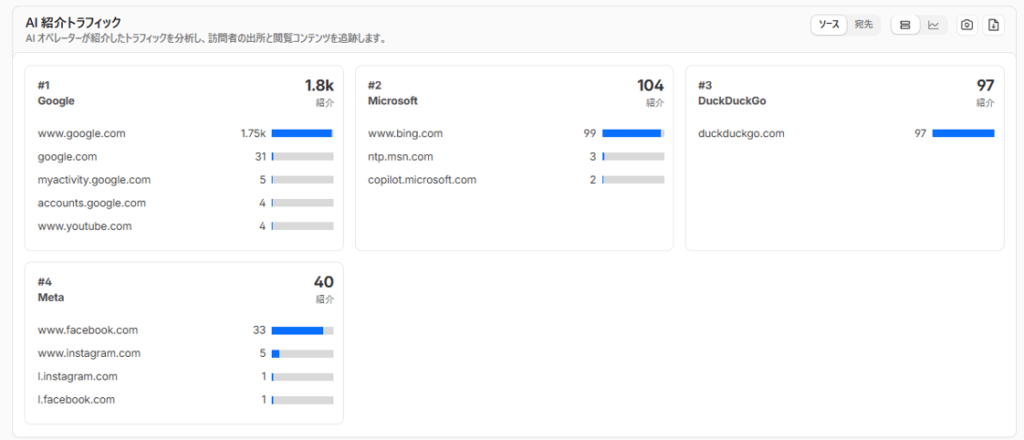
ページ上部の「AI紹介トラフィック」セクションでは、AIがあなたのサイトをどれだけ参照・紹介したかを企業別に表示します。Google、Microsoft(Bing)、DuckDuckGo、Metaなどのランキング形式で確認できます。
「AIが自分のサイトを引用してくれているか?」を知りたい場合に特に役立ちます。
時間経過によるリクエスト
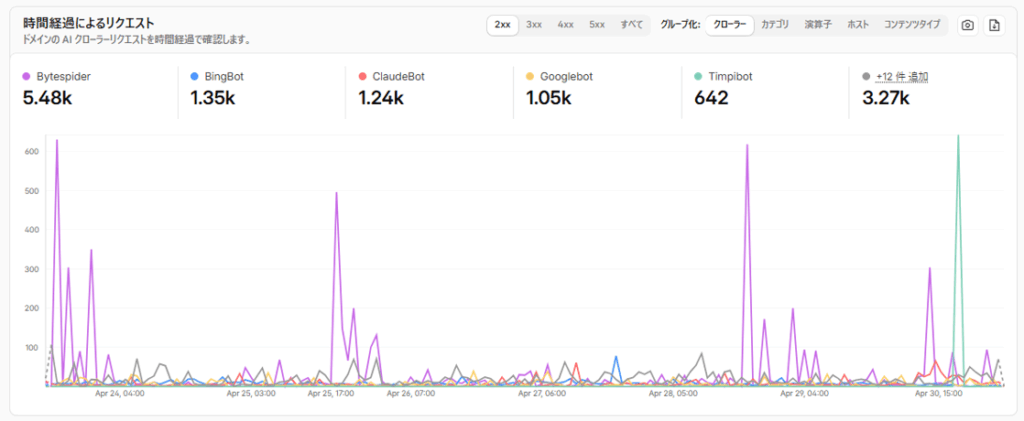
どのクローラーがいつ、どれくらいアクセスしてきたかを時系列グラフで確認できます。急激なスパイク(急増)があった場合、特定のAIが一気にクロールしたことを意味します。
時間経過によるデータ転送
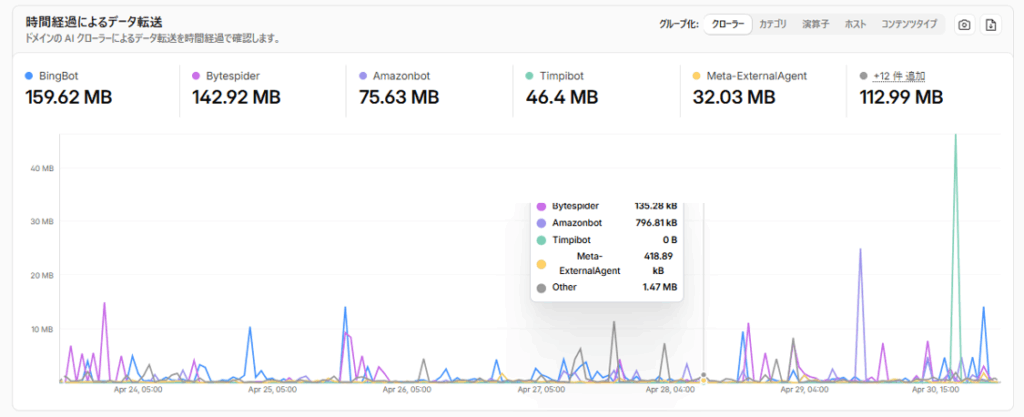
クローラーが実際に持ち出したデータ量(バイト数)のグラフです。リクエスト数が少なくてもデータ転送量が多い場合、ページあたりのコンテンツ量が多いことを示します。
コンテンツ形式
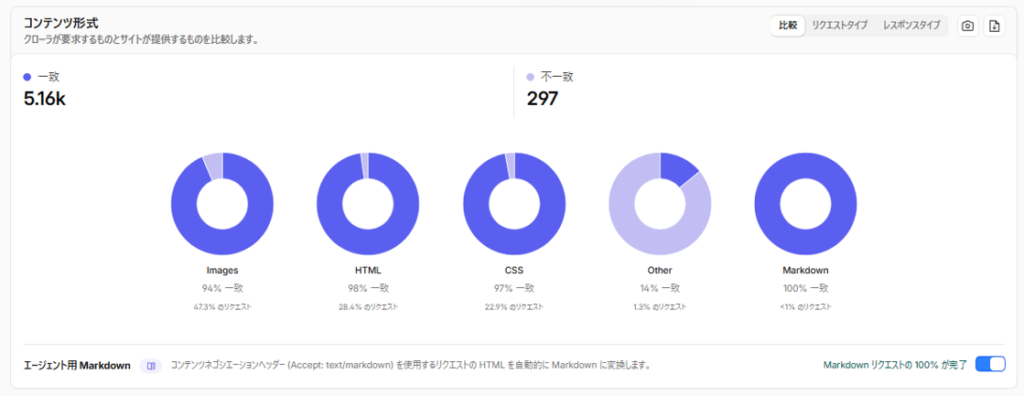
AIクローラーがどの種類のコンテンツにアクセスしているかをドーナツグラフで表示します。Images、HTML、CSS、Markdownなどの割合が確認でき、「AIが主にどんなファイルを取得しているか」がわかります。
ステータスコード分析
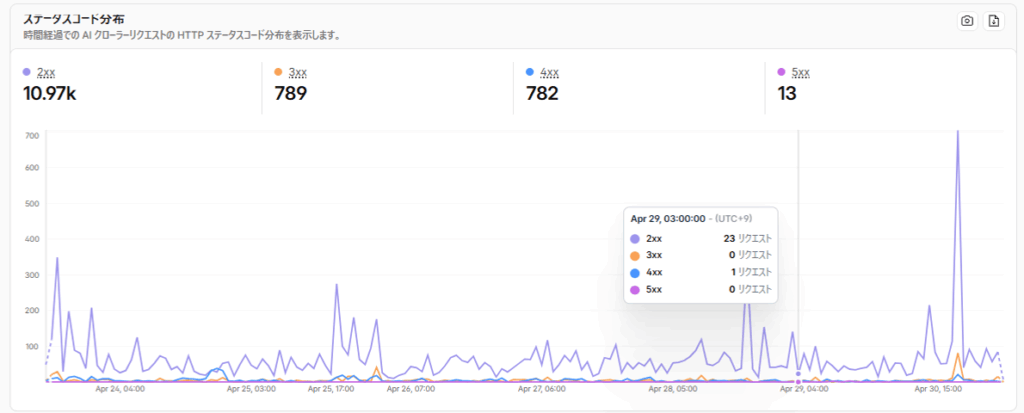
AIクローラーへのレスポンスがどのHTTPステータスコードだったかを時系列で確認できます。
| ステータス | 意味 |
| 2xx | 正常(アクセス成功) |
| 3xx | リダイレクト |
| 4xx | クライアントエラー(ブロック含む) |
| 5xx | サーバーエラー |
ブロック設定が正しく機能しているか確認したいときは、4xxの件数を見るとよいです。
最もクロールされたパス
どのページURLがAIに最もアクセスされているかを確認できます。
特定の記事や商品ページが集中的にクロールされていることに気づけます。
ディレクティブページ — robots.txtの状態を確認・管理する
ディレクティブページでは、「robots.txt」というAIやクローラーへの指示ファイルに関する情報を確認・管理できます。
robots.txtとは
robots.txtとは、Webサイトの特定のディレクトリに置くテキストファイルで、クローラーに対して「ここには来ないでください」という指示を書くためのものです。
ただし、あくまで「お願い」であり、すべてのクローラーがこれを守るとは限りません。
管理されたrobots.txt
ページ上部のトグルスイッチをオンにすると、Cloudflareが自動でrobots.txtを管理してくれます。有効にすることで、コンテンツがAIトレーニングに使われないよう、CloudflareがAIクローラーへシグナルを送ります。
自分でrobots.txtを編集する必要がなくなるため、非エンジニアのサイトオーナーには特に便利な機能です。
エージェントの準備状況
「エージェントの準備状況」パネルでは、robots.txtと関連設定をテストし、サイトがAIエージェントに対応できているかを確認できます。「サイトを確認」リンクから実際にチェックできます。
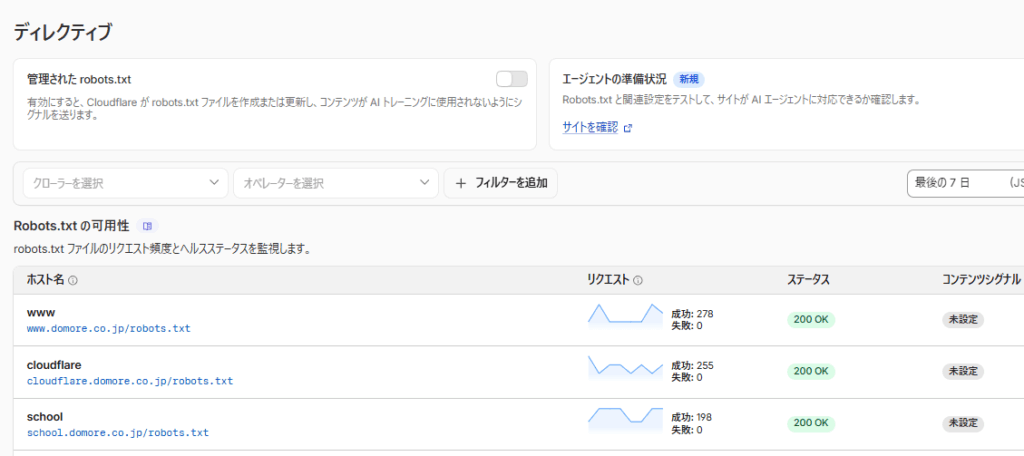
robots.txtの可用性
この表では、ドメインごとのrobots.txtファイルの状態を一覧で確認できます。
| 列名 | 意味 |
| ホスト名 | サブドメインを含むドメイン名 |
| リクエスト | robots.txtへのアクセス数(成功/失敗) |
| ステータス | 200 OK / 404 Not Found / 500エラーなど |
| コンテンツシグナル | AIトレーニング拒否のシグナルが設定されているか |
実際の画面では、200 OK(正常)のほか、404 Not Found(robots.txtが存在しない)や500 Internal Server Error(サーバーエラー)になっているサブドメインも確認できます。404や500になっているドメインは、robots.txtが機能していない状態なので、対応が必要です。
「コンテンツシグナル」列が「未設定」のままの場合、AIに対してコンテンツ使用の可否が何も伝わっていない状態です。前述の「管理されたrobots.txt」をオンにするか、自分でrobots.txtを設定することで改善できます。
robots.txtの違反
下部の「robots.txtの違反」セクションでは、robots.txtで拒否したパスにもかかわらずアクセスしてきたクローラーを確認できます。違反が多いクローラーはブロックの候補になります。
AIクローラーの訪問数を継続的に把握するには
Googleアナリティクスでアクセス数を定期的に確認するように、AIクローラーの訪問状況も定点観測する習慣をつけておくと、AIOの効果測定に役立ちます。
見るべき場所は主に2つです。
メトリクスページ
日常的なチェックの起点になります。「時間経過によるリクエスト」グラフでは、AIクローラー全体の訪問数の増減をトレンドとして確認できます。GAでセッション数の推移を見る感覚に近いイメージです。また「AI紹介トラフィック」では、GoogleやPerplexityといったAIサービスが実際に自分のサイトを引用・紹介しているかどうかを企業別に把握できます。
クローラーページ
個別のAIごとの訪問数を見たい場合はクローラーページのリクエスト列を確認します。どのAIが最も多く来ているかが一目でわかります。
なお、概要ページは「異変に気づいたときに最初に開く場所」として使うと便利です。全体のサマリーが表示されるため、急激な増減があればここで把握できます。
最初から全部使いこなす必要はありません。
AI Crawl Controlは設定不要で自動的にデータを収集し始めているため、気軽に開始できます。
ダッシュボードを開いて状況を確認してみましょう。
Web表示スピード改善・セキュリティ対策のCloudflare
導入のご相談だけでなく、運用フェーズでのサポートも承ります。
DDoS攻撃や悪質なBot(ボット)からのアクセスを防ぎたい方、WAF機能やプランの詳細を知りたい方、
国内エンジニアによる安心の運用サポートをご希望の方も、ぜひお気軽にお問い合わせください。